우리가 로그를 저장할 때 ClickHouse를 사용하는 이유
2024년 9월 27일

오늘은 저희가 Cloud WAAP 서비스를 개발하면서 겪은 대용량 HTTP 요청 로그의 저장과 분석에 대한 고민, 그리고 그 해결책으로 ClickHouse를 선택하고 최적화한 과정을 공유하고자 합니다.
도입 배경
Cloud WAF 서비스를 운영하면서 매일 수억 건 이상의 HTTP 요청이 발생합니다. 이러한 방대한 로그 데이터를 어떻게 효율적으로 저장하고 빠르게 분석할 수 있을까? 이는 서비스의 안정성과 성능, 그리고 고객에게 제공하는 가치와 직결되는 중요한 문제였습니다.
전통적인 데이터베이스로는 증가하는 데이터량을 감당하기 어렵고, 분석 속도도 만족스럽지 않았습니다. 이에 따라 대용량 데이터 처리를 위한 새로운 솔루션이 필요했고, 여러 후보 중에서 ClickHouse를 도입하게 되었습니다.
ClickHouse란 무엇인가

ClickHouse는 러시아의 IT 기업 Yandex에서 개발한 오픈 소스 컬럼 지향 분산 데이터베이스 관리 시스템(DBMS)입니다. 실시간 분석 처리를 위해 설계되었으며, 다음과 같은 특징을 가지고 있습니다:
고성능: 대용량 데이터에 대한 실시간 질의 처리 가능
컬럼 지향 저장: 데이터 압축과 I/O 효율성이 높음
분산 처리 지원: 수평 확장을 통해 성능 향상
풍부한 기능: 다양한 데이터 타입과 함수 지원
ClickHouse를 선택한 이유
저희가 ClickHouse를 선택한 이유는 여러 가지가 있지만, 그중에서도 핵심적인 네 가지를 소개하겠습니다.
1. 컬럼 지향 데이터베이스의 이점
컬럼 지향 데이터베이스는 데이터를 컬럼 단위로 저장합니다. 이는 동일한 타입의 데이터가 연속적으로 저장되기 때문에 압축 효율이 높아지고, 필요한 컬럼만 읽어들일 수 있어 I/O 성능이 향상됩니다.
압축 효율 증가: 동일한 데이터 타입이 연속적으로 저장되어 압축 알고리즘의 효율 극대화
쿼리 성능 향상: 필요한 컬럼만 접근하여 디스크 I/O 감소
데이터 스캔 속도 개선: 불필요한 데이터 접근 최소화
2. 효율적인 인덱싱 (Sparse Index)
ClickHouse의 Sparse Index는 데이터의 블록 단위로 인덱스를 생성합니다. 이는 전체 데이터에 인덱스를 생성하는 것보다 저장 공간을 절약하면서도 빠른 검색이 가능하도록 합니다.
저장 공간 절약: 전체 인덱스 대비 작은 크기
검색 속도 향상: 필요한 블록만 빠르게 찾아서 읽어들임
유연한 설정: 블록 크기와 인덱싱 간격 조절 가능
3. 고압축 저장 (LZ4 Algorithm)

데이터 압축은 저장 공간을 절약하고 I/O 성능을 향상시키는 데 중요합니다. ClickHouse는 LZ4 압축 알고리즘을 기본으로 사용하여 높은 압축률과 빠른 압축/해제 속도를 제공합니다.
빠른 속도: 실시간 처리를 위한 빠른 압축/해제
높은 압축률: 저장 공간 절약으로 비용 감소
낮은 CPU 오버헤드: 서버 리소스 효율적 사용
4. 수평 확장성
ClickHouse는 분산 아키텍처를 지원하여 노드를 추가함으로써 수평 확장이 가능합니다. 이는 데이터 증가에 따라 시스템을 유연하게 확장할 수 있어 서비스의 안정성과 성능을 유지할 수 있습니다.
노드 추가로 성능 향상: 선형적인 처리 능력 증가
고가용성 보장: 노드 간 데이터 복제와 페일오버 지원
부하 분산: 쿼리와 데이터 저장의 분산 처리
ClickHouse 최적화 과정

ClickHouse를 도입한 이후, 저희는 시스템의 성능을 극대화하기 위해 여러 가지 최적화 작업을 진행했습니다.
1. Cap'n Proto를 통한 데이터 전송 최적화
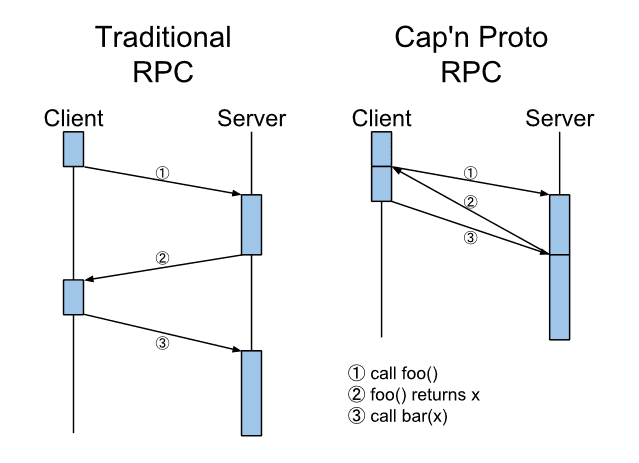
데이터 직렬화에는 Cap'n Proto 포맷을 사용하였습니다. 이는 매우 빠르고 가벼우며, 다음과 같은 이점이 있습니다.
빠른 직렬화/역직렬화 속도: 네트워크 전송 시간 단축
낮은 오버헤드: CPU 사용량 감소
간편한 스키마 정의: 유지 보수성과 확장성 향상
이를 통해 서버와 ClickHouse 사이의 데이터 전송 효율을 극대화할 수 있었습니다.
2. 대용량 배치 처리
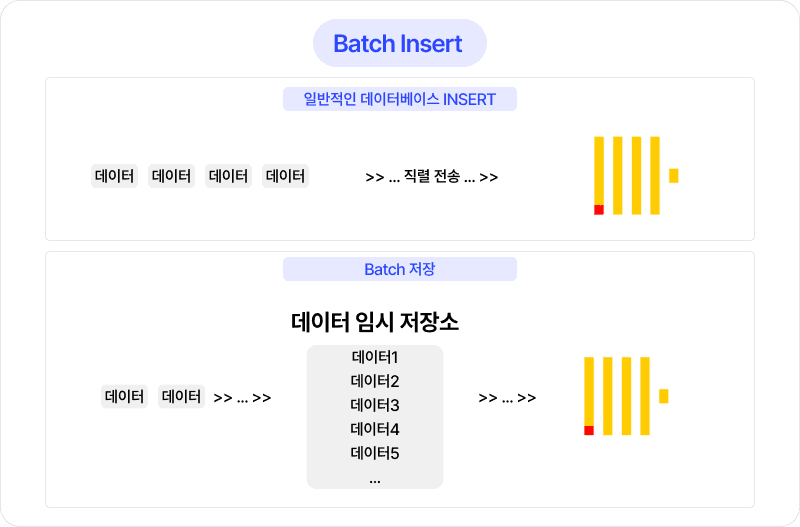
데이터를 실시간으로 하나씩 전송하는 대신, 대용량 배치(batch)로 묶어서 처리하였습니다.
네트워크 호출 감소: 패킷 오버헤드 최소화
I/O 효율성 향상: 디스크와 네트워크의 연속적 데이터 처리
처리량 증가: ClickHouse의 벡터화 처리 최적화 활용
이러한 배치 처리를 통해 전체 시스템의 처리량과 응답 속도를 향상시켰습니다.
3. 데이터 파티셔닝 전략
데이터의 효율적인 관리와 쿼리 성능 향상을 위해 데이터 파티셔닝을 적용하였습니다.
시간 단위 파티셔닝:
toStartOfHour(time)함수를 사용하여 시간별 파티션 생성쿼리 성능 향상: 특정 시간대의 데이터만 스캔하여 응답 속도 개선
데이터 관리 용이: 오래된 데이터의 손쉬운 아카이빙 및 삭제
이를 통해 데이터 관리의 복잡성을 줄이고, 쿼리의 효율성을 높일 수 있었습니다.
4. 데이터 스키핑 인덱스 활용
데이터 스키핑 인덱스는 특정 컬럼의 최소값과 최대값을 저장하여 쿼리 시 불필요한 데이터 블록을 건너뛸 수 있게 해줍니다.
쿼리 속도 향상: 읽어야 할 블록의 수 감소
자원 사용 최적화: CPU와 디스크 I/O 부담 감소
적용의 용이성: 필요한 컬럼에만 선택적으로 적용 가능
이를 통해 복잡한 쿼리에서도 높은 성능을 유지할 수 있었습니다.
마치며
저희는 ClickHouse를 도입하고 다양한 최적화 작업을 통해 대용량 HTTP 요청 로그를 효율적으로 저장하고 빠르게 분석할 수 있게 되었습니다. 이는 Cloud WAF 서비스의 안정성과 성능 향상, 그리고 고객에게 제공하는 가치의 극대화로 이어졌습니다.
앞으로도 지속적인 연구와 최적화를 통해 더 나은 서비스를 제공하도록 노력하겠습니다. 이 과정에서 얻은 경험과 지식을 계속해서 공유하겠습니다. 긴 글 읽어주셔서 감사합니다.

